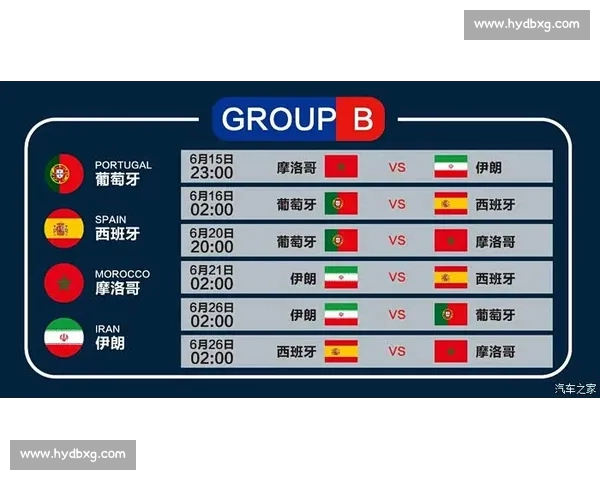
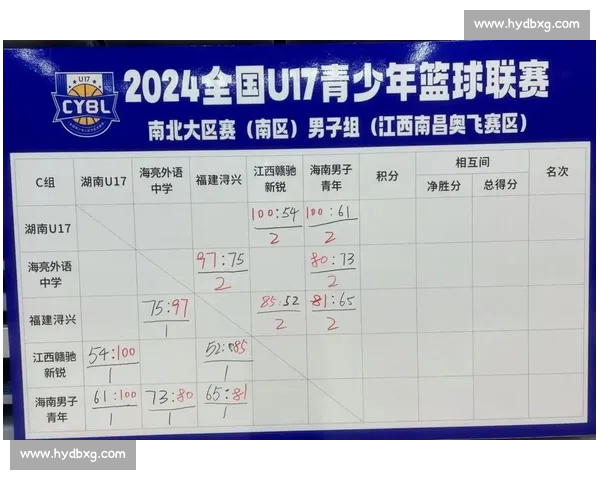
文章摘要的内容: 足球数据分析正在从“经验判断”走向“模型驱动”,但在这一过程中,胜率迷信、样本误读、指标滥用和模型偏差等问题频频出现,导致分析结果与真实比赛严重背离。本文以“从胜率到模型偏差揭示足球数据分析常见误区全解析与实战决策陷阱”为核心,系统梳理足球数据分析中最容易被忽视却影响巨大的认知误区。文章将从胜率指标的表面陷阱、数据样本与变量选择的偏差、模型构建与验证的常见错误,以及数据分析在实战决策中的失真风险四个方面展开,层层剖析足球数据如何在不当使用下误导判断。通过理论分析与实际场景结合,帮助读者建立更理性、更审慎的数据思维,真正理解数据的边界与价值,从而在足球分析与决策中避免“看似科学、实则失真”的常见陷阱。
在足球数据分析中,胜率往往被视为最直观、最有说服力的指标之一。无论是球队胜率、主客场胜率,还是某位教练执教胜率,都常被直接用于预测比赛结果。然而,胜率本身只是历史结果的统计,并不天然具备预测未来的能力,这一点经常被忽略。
一个常见误区在于忽视胜率背后的对手质量差异。某支球队在弱队密集赛程中取得高胜率,并不意味着其真实实力强于一支在强队对抗中胜率略低的球队。如果不对赛程强度进行校正,单纯比较胜率,往往会得出完全错误的结论。
此外,胜率对样本规模极度敏感。在样本数量较小的情况下,胜率波动巨大,却常被解读为“趋势”或“状态”。例如,三场连胜就被视为状态火热,但从统计角度看,这样的样本远不足以支撑稳定判断。
更深层的问题在于,胜率无法反映比赛过程。依靠点球、乌龙或红牌获胜的比赛,与场面碾压取得的胜利,在胜率统计中权重完全相同,这种信息损失是胜率指标无法弥补的结构性缺陷。
足球数据分析的基础是样本,而样本选择本身就可能埋下偏差的种子。许多分析者在无意中只选取“看起来相关”的数据,却忽略了整体样本的代表性,从而导致结论失真。
时间窗口选择是最典型的问题之一。过短的时间窗口容易受到偶然事件干扰,而过长的时间窗口又可能掩盖球队阵容、战术和状态的变化。如果不根据分析目的灵活调整时间维度,数据结论往往既不敏感也不准确。
另一个常见偏差来自于人为筛选条件。例如,只分析某队在“主场且天气良好”的比赛,虽然看似精准,但样本数量骤减,随机性急剧上升,反而降低了分析的可靠性。
此外,忽视缺失数据和异常值同样危险。伤病、红牌、临时换帅等极端事件如果被简单剔除,可能会美化模型表现,却让模型在真实环境中彻底失效。
星空(中国)xingkong·官方网站,星空(中国)xingkong·官方网站-科技股份有限公司,星空中国,星空(中国)xingkong·官方网站,星空(中国)xingkong·官方网站随着机器学习和统计模型的普及,越来越多的足球分析开始依赖复杂模型,但模型复杂度的提升并不必然带来决策质量的提升。相反,模型构建阶段的误区往往更加隐蔽。
过拟合是最普遍的问题。模型在历史数据上表现惊艳,却在新比赛中预测失准,其根本原因在于模型学习了噪声而非规律。在足球这种高随机性的运动中,过拟合几乎是必然风险。
变量选择不当也是模型偏差的重要来源。将高度相关的变量同时纳入模型,或引入与结果无直接因果关系的指标,都会扭曲模型权重,使输出结果看似精细却缺乏解释力。
更容易被忽视的是模型验证方法的缺失。许多分析只展示预测准确率,却没有进行交叉验证或样本外测试,这使得模型性能评估本身就建立在不稳固的基础之上。
即便数据分析在理论层面相对严谨,落地到实战决策中仍然可能出现严重偏差。原因在于,足球比赛不仅是数据问题,更是动态博弈和人类行为的集合。
一个典型陷阱是“数据权威化”。当数据结论与教练或分析师的直觉冲突时,往往选择盲目服从数据,而忽视战术背景、球员心理和临场信息,导致决策僵化。
另一个问题在于忽略对手的反应。数据模型通常基于历史行为,而比赛中的对手会根据预期进行调整。当双方都依赖相似数据逻辑时,模型优势可能迅速消失。
最后,决策节奏失衡也是常见问题。过度频繁地根据短期数据调整策略,容易引发系统性波动,使球队或分析策略陷入“越调越乱”的恶性循环。
总结:
从胜率到模型偏差,足球数据分析中的误区并非源于数据本身,而是源于对数据能力的过度信任与对其局限的忽视。胜率的表面直观、样本选择的主观倾向、模型构建的技术迷思,共同构成了看似科学却暗藏风险的分析体系。
真正成熟的足球数据分析,应当将数据视为辅助工具而非裁判,结合比赛背景、专业经验与持续验证机制,才能在复杂多变的实战环境中发挥价值。只有认清误区、理解偏差,数据才能成为决策的助力,而非陷阱。</